Projects
From SpeechWiki
(smaragdis: class for sound input) |
|||
| (18 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
Here are some projects that [[SST People]] are working on. For another view, see our [http://www.isle.uiuc.edu/pubs Publications]. | Here are some projects that [[SST People]] are working on. For another view, see our [http://www.isle.uiuc.edu/pubs Publications]. | ||
| - | ===Phonetics, Phonology, Semantics=== | + | ===SST Group Meetings=== |
| + | |||
| + | * [[SST Group Meetings]] | ||
| + | |||
| + | ===Phonetics, Phonology, Semantics=== | ||
; Prosody and Phonology in Automatic Speech Recognition (Landmark-Based Speech Recognition) | ; Prosody and Phonology in Automatic Speech Recognition (Landmark-Based Speech Recognition) | ||
| Line 20: | Line 24: | ||
; GroupScope --- Dynamics of Medium-Sized Groups | ; GroupScope --- Dynamics of Medium-Sized Groups | ||
| - | : [[ | + | : [[GroupScope]] |
===Language Acquisition, Language Contact, Variability, and Disability=== | ===Language Acquisition, Language Contact, Variability, and Disability=== | ||
| Line 56: | Line 60: | ||
: [http://www.isle.uiuc.edu/AVICAR/ AVICAR Database] | : [http://www.isle.uiuc.edu/AVICAR/ AVICAR Database] | ||
| + | ; Smaragdis collaboration | ||
| + | : [[Image:Smaragdis-130218.jpg]] | ||
| + | : [[Image:Smaragdis-130311.jpg]] | ||
| + | |||
| + | Pseudocode spec for the sound input class | ||
| + | (and also output later, but not read-and-write): | ||
| + | |||
| + | class input_t{ | ||
| + | // Definition of stream characteristics | ||
| + | class specs_t{ | ||
| + | size_t channels; | ||
| + | double sample_rate; | ||
| + | enum sample_format; | ||
| + | }; | ||
| + | |||
| + | // | ||
| + | // Constructors | ||
| + | // | ||
| + | |||
| + | input_t( ??? stream, bool in_or_out, size_t ch, double sr, enum frm) | ||
| + | { | ||
| + | switch( stream){ | ||
| + | case "file" | ||
| + | use ffmpeg | ||
| + | case "socket" | ||
| + | use homebrew code? | ||
| + | case "url" | ||
| + | use VLC? | ||
| + | case "adc" | ||
| + | Use portaudio | ||
| + | case "dac" | ||
| + | Use portaudio | ||
| + | } | ||
| + | } | ||
| + | |||
| + | input_t( ??? stream, input_t example); // copy stream attributes | ||
| + | input_t( ??? stream, input_t::specs_t example); // copy stream attributes | ||
| + | |||
| + | Assignment/copy operators | ||
| + | |||
| + | // | ||
| + | // Destructor | ||
| + | // | ||
| + | |||
| + | ~input_t() // bookkeeping with closing file/net/etc. | ||
| + | |||
| + | // | ||
| + | // Utilities | ||
| + | // | ||
| + | |||
| + | double sample_rate(); | ||
| + | size_t channels(); | ||
| + | enum sample_format(); | ||
| + | bool eof(); | ||
| + | bool(); | ||
| + | |||
| + | // | ||
| + | // Seeking | ||
| + | // | ||
| + | |||
| + | seek( size_t s); // move to sample frame s | ||
| + | seek( double t); // move to second t | ||
| + | |||
| + | // | ||
| + | // Reading | ||
| + | // output should be channels by sample frames | ||
| + | |||
| + | array<T> &read( size_t n, size_t offset, int channel_mask); // sample frames | ||
| + | array<T> &read( double n, double offset, int channel_mask); // seconds | ||
| + | |||
| + | // | ||
| + | // Writing | ||
| + | // | ||
| + | |||
| + | write( array<T> &x, size_t offset, int channel_mask); // sample frames | ||
| + | write( array<T> &x, double offset, int channel_mask); // seconds | ||
| + | |||
| + | write_add( array<T> &x, size_t offset, int channel_mask); // sample frames | ||
| + | write_add( array<T> &x, double offset, int channel_mask); // seconds | ||
| + | }; | ||
| + | |||
| + | We are going for a blocking interface instead of cumbersome callbacks for now. The stream parameters when reading can be used to perform | ||
| + | +on the fly resampling and channel remapping. I'm attaching the board doodling in case I missed something. | ||
| + | |||
| + | We are currently working on the getting code to work for the simple case: | ||
| + | |||
| + | main() | ||
| + | { | ||
| + | input_t in( ...); | ||
| + | |||
| + | while( in){ | ||
| + | x = in.read( ...); | ||
| + | y = feature( x); | ||
| + | plot( y); | ||
| + | } | ||
| + | } | ||
| + | |||
| + | I'm working on the feature object, Camille is working on the input object. | ||
==See also== | ==See also== | ||
| - | [http://www.isle. | + | * [http://www.isle.illinois.edu/sst/pubs/ SST publications] |
| + | * [http://www.isle.illinois.edu/sst/ SST group web page] | ||
| + | * [[Special:Upload]] | ||
Latest revision as of 23:06, 11 March 2013
Here are some projects that SST People are working on. For another view, see our Publications.
Contents |
SST Group Meetings
Phonetics, Phonology, Semantics
- Prosody and Phonology in Automatic Speech Recognition (Landmark-Based Speech Recognition)
- Group Meeting Schedules and Slides
- Landmark-Based Speech Recognition
- Prosody of Disfluency
- Very Large Corpus ASR/ Mixed-Units ASR
- Large Vocabulary speech recognition using mixed units on fisher corpus
- Articulatory Feature Transcription
- Transcription Guidelines
- Phone-to-Feature Mapping
- Meeting Summaries
- Resources
Group dynamics and Discourse
- GroupScope --- Dynamics of Medium-Sized Groups
- GroupScope
Language Acquisition, Language Contact, Variability, and Disability
- Multi-Dialect Speech Recognition and Machine Translation for Qatari Broadcast TV
- Multi Dialect Arabic
- Cross-Language Transfer Learning
- Linguistic Diversity References
- Star Challenge competition
- Dynamics of Second Language Fluency
- Group Meeting Schedules and Slides
- Description
- Data Description
- Universal Access
- Group Meeting Schedules and Slides
- Description
- UASpeech Database
Multimodal Fusion, Speech and Non-Speech
- Audiovisual Event Detection and Visualization
- Group Meeting Schedules and Slides
- Papers
- Visualization Experiments
- Mobile Platform Acoustic-Frequency Environmental Tomography (was Dereverberation)
- Group Meeting Schedules
- Project Status and Working Notes
- Audiovisual Speech Recognition
- Description
- AVICAR Database
- Smaragdis collaboration
-
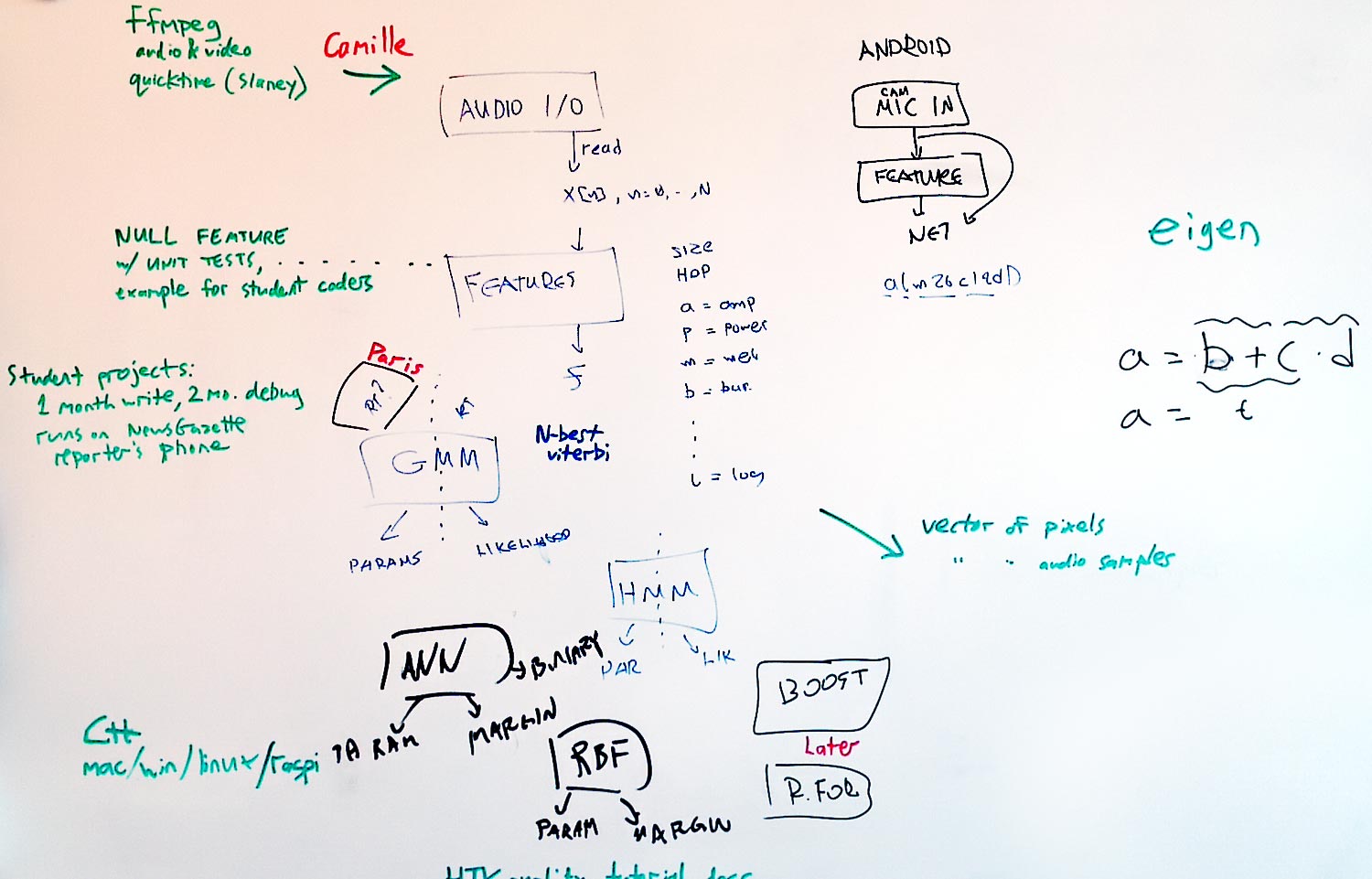
-



Pseudocode spec for the sound input class (and also output later, but not read-and-write):
class input_t{ // Definition of stream characteristics class specs_t{ size_t channels; double sample_rate; enum sample_format; };
// // Constructors //
input_t( ??? stream, bool in_or_out, size_t ch, double sr, enum frm) { switch( stream){ case "file" use ffmpeg case "socket" use homebrew code? case "url" use VLC? case "adc" Use portaudio case "dac" Use portaudio } }
input_t( ??? stream, input_t example); // copy stream attributes input_t( ??? stream, input_t::specs_t example); // copy stream attributes
Assignment/copy operators
// // Destructor //
~input_t() // bookkeeping with closing file/net/etc.
// // Utilities //
double sample_rate(); size_t channels(); enum sample_format(); bool eof(); bool();
// // Seeking //
seek( size_t s); // move to sample frame s seek( double t); // move to second t
// // Reading // output should be channels by sample frames
array<T> &read( size_t n, size_t offset, int channel_mask); // sample frames array<T> &read( double n, double offset, int channel_mask); // seconds
// // Writing //
write( array<T> &x, size_t offset, int channel_mask); // sample frames write( array<T> &x, double offset, int channel_mask); // seconds
write_add( array<T> &x, size_t offset, int channel_mask); // sample frames write_add( array<T> &x, double offset, int channel_mask); // seconds };
We are going for a blocking interface instead of cumbersome callbacks for now. The stream parameters when reading can be used to perform +on the fly resampling and channel remapping. I'm attaching the board doodling in case I missed something.
We are currently working on the getting code to work for the simple case:
main() { input_t in( ...);
while( in){ x = in.read( ...); y = feature( x); plot( y); } }
I'm working on the feature object, Camille is working on the input object.